Splunk - Contenu d'un index
Alasta 23 Novembre 2019 splunk splunk admin index bucket
Description : On va découvrir le contenu d'un index.
Contenu d’un index :
Un index contient :
- Les données en raw compressées (rawdata)
- Des données indéxées qui pointent vers les rawdata (tsidx)
- D’autres fichiers de metadata
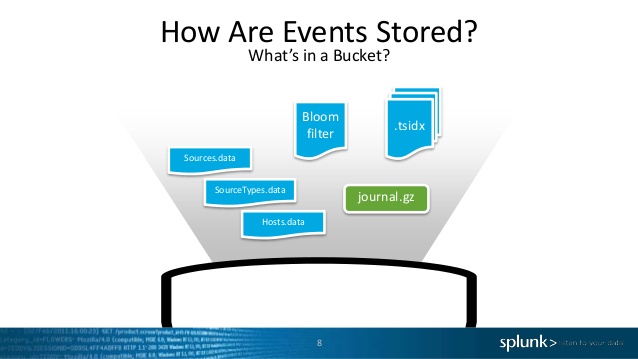
Rappel des PATHs par défaut d’un index :
Arborescence d’un index :
Voici le contenu d’un index, ici j’ai pris _introstection.
_introspection
├── colddb
├── datamodel_summary
│ ├── 47_7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── 7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── DM_SplunkAppForFortinet_ftnt_fos
│ │ ├── done
│ │ ├── metadata.csv
│ │ └── metadata_checksum
│ ├── 48_7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── 7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── DM_SplunkAppForFortinet_ftnt_fos
│ │ ├── done
│ │ ├── metadata.csv
│ │ └── metadata_checksum
│ ├── 49_7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── 7685E1F6-8087-46DF-A6AF-17FF3DCE7E12
│ │ └── DM_SplunkAppForFortinet_ftnt_fos
│ │ ├── hot_done
│ │ └── metadata.csv
│ ├── manifest.csv
│ ├── manifest.csv.changed
│ └── notify
├── db
│ ├── .bucketManifest
│ ├── .db_1506763187_1506761294_1.rbsentinel
│ ├── .db_1511100934_1511095411_9.rbsentinel
│ ├── .db_1515841831_1515841153_17.rbsentinel
│ ├── CreationTime
│ ├── GlobalMetaData
│ ├── db_1569666163_1569665619_30.rbsentinel
│ ├── db_1574113908_1574113735_47
│ │ ├── .rawSize
│ │ ├── 1574113908-1574113735-17669199871922402432.tsidx
│ │ ├── Hosts.data
│ │ ├── SourceTypes.data
│ │ ├── Sources.data
│ │ ├── Strings.data
│ │ ├── bloomfilter
│ │ ├── bucket_info.csv
│ │ ├── optimize.result
│ │ ├── rawdata
│ │ │ ├── journal.gz
│ │ │ ├── slicemin.dat
│ │ │ └── slicesv2.dat
│ │ └── splunk-autogen-params.dat
│ ├── db_1574114930_1574113909_48
│ │ ├── .rawSize
│ │ ├── 1574114930-1574113909-6381335608178854672.tsidx
│ │ ├── Hosts.data
│ │ ├── SourceTypes.data
│ │ ├── Sources.data
│ │ ├── Strings.data
│ │ ├── bloomfilter
│ │ ├── bucket_info.csv
│ │ ├── optimize.result
│ │ ├── rawdata
│ │ │ ├── journal.gz
│ │ │ ├── slicemin.dat
│ │ │ └── slicesv2.dat
│ │ └── splunk-autogen-params.dat
│ └── hot_v1_49
│ ├── .rawSize
│ ├── 1574506477-1574506433-6604304948416566232.tsidx
│ ├── 1574506487-1574506487-6625743269070971518.tsidx
│ ├── 1574506493-1574506493-6651501210147316447.tsidx
│ ├── 1574506504-1574506504-6712552602596921944.tsidx
│ ├── Hosts.data
│ ├── SourceTypes.data
│ ├── Sources.data
│ ├── Strings.data
│ ├── bucket_info.csv
│ ├── rawdata
│ │ ├── journal.gz
│ │ ├── slicemin.dat
│ │ └── slicesv2.dat
│ ├── splunk-autogen-params.dat
│ └── splunk-need-optimize.dat
└── thaweddb
21 directories, 57 filesDescription des fichiers principaux :
.bucketManifest : fichier de metadata, contenant la liste de tous les buckets de l’index, event_count, host_count ….
.db_1506763187_1506761294_1.rbsentinel
.db_1511100934_1511095411_9.rbsentinel
.db_1515841831_1515841153_17.rbsentinel
.rawSize : A VALIDER : The volume in bytes of the raw data files in each bucket. This value represents the volume before compression and the addition of index files.
CreationTime : Fichier contenant le timestamp de la création de d’index.
Hosts.data : fichier de metadata, contenant les hosts du bucket.
SourceTypes.data : fichier de metadata, contenant les Sourcetypes du bucket.
Sources.data : fichier de metadata, contenant les Sources de données du bucket.
Strings.data : fichier de metadata, contenant
bloomfilter :
bucket_info.csv : a l’ait d’indiquer le timestamp de début et fin du bucket et si le bucket et frozen.
db_1569666163_1569665619_30.rbsentinel
journal.gz : lot d’événements (slice) raw compréssés
optimize.result : resultat optimisation index ??
slicemin.dat : les slices.dat mappent les tsidx avec le slice (journal.gz)
slicesv2.dat
splunk-autogen-params.dat
splunk-need-optimize.dat
1574113908-1574113735-17669199871922402432.tsidx : fichier TimeSeries index
1574114930-1574113909-6381335608178854672.tsidx
1574506477-1574506433-6604304948416566232.tsidx
1574506487-1574506487-6625743269070971518.tsidx
1574506493-1574506493-6651501210147316447.tsidx
1574506504-1574506504-6712552602596921944.tsidx
Nommage des buckets :
Le nom dépend :
- de l’état du bucket : hot, warm cold ou thawed
- le type de bucket : non-clustered,clustered originating ou clustered replicated

- **
** et ** ** sont des timestamps indiquant l'age des données dans le bucket. Le timestamps est exprimé en UTC epoch time (en secondes). - **
** est l'ID du bucket. Pour un clustered bucket, l'original et le répliqué ont le même localid. - **
** est le guid de la source du peer node. Le guid est localisé dans le fichier **$SPLUNK_HOME/etc/instance.cfg** de chaque instance.
Exemple db_1223658000_1223654401_2835 :
Bucket warm, non-clustered, entre le 10/10/2008 à 17:00:00 et 10/10/2008 à 16:00:01 avec le localid 2835.
Note :
Dans un cluster, le bucket original et le replicat ont le même nom excepté le préfix (db et rb).
Dans un cluster, lorsque le bucket est en cours de tranfert (replicat), les données sont envoyées dans un dossier temporaire sur le peer cible, ce hot bucket est identifié par **
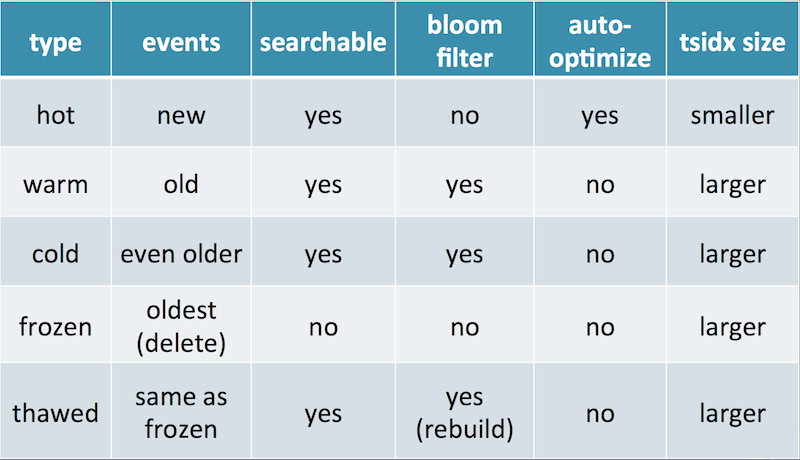
Récapitilatif sous forme de tableau :
Annexes :
Doc officiel - Managing Indexers and Clusters of Indexers
Understanding how “buckets” work